Vi laster inn data fra internett
Contents
Vi laster inn data fra internett¶
Vi kan finne datafiler lagt ut på nettet. Disse kan vi laste inn i Python på en elegant måte ved å bruke pandas. Vi viser ved hjelp av en del eksempler.
Eksempel 1¶
Filen https://vincentarelbundock.github.io/Rdatasets/csv/quantreg/gasprice.csv innhol- der tidsserie for ukentlige bensinpriser i USA i perioden 1990:8-2003:26
a) Lag en grafisk framstilling av hele tidsserien.
b) Lag en grafiske gramstilling der du kun ser på årene 2000-2003.
Løsning:¶
import pandas as pd # For å lese og behandle CSV-filer
import matplotlib.pyplot as plt # For plotting
url = "https://vincentarelbundock.github.io/Rdatasets/csv/quantreg/gasprice.csv"
# Vi leser inn data fra URLen og lagrer det i en dataframe som vi kaller df:
df = pd.read_csv(url, index_col=0)
df
| time | value | |
|---|---|---|
| 1 | 1990.134615 | 126.6 |
| 2 | 1990.153846 | 127.2 |
| 3 | 1990.173077 | 132.1 |
| 4 | 1990.192308 | 133.3 |
| 5 | 1990.211538 | 133.9 |
| ... | ... | ... |
| 691 | 2003.403846 | 157.9 |
| 692 | 2003.423077 | 160.4 |
| 693 | 2003.442308 | 159.1 |
| 694 | 2003.461538 | 160.9 |
| 695 | 2003.480769 | 161.7 |
695 rows × 2 columns
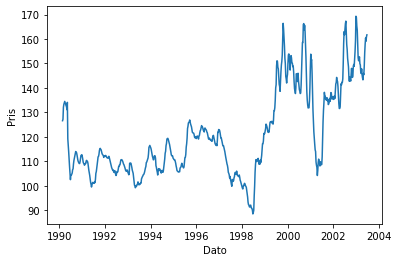
Vi kan nå plotte disse tallene ved å bruke time på x-aksen og value på y-aksen. Dette kan gjøres ved å bruke plt.plot(). Vi kan også bruke en egen plotte-metode på datarammen df som pandas gir oss. Vi viser begge metodene.
# Metode 1
x = df["time"] # x er en liste med datoer
y = df["value"] # y er en liste med priser
plt.plot(x, y)
plt.xlabel("Dato")
plt.ylabel("Pris")
plt.show()
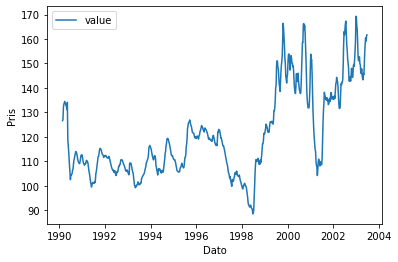
# Metode 2
df.plot("time", "value")
plt.xlabel("Dato")
plt.ylabel("Pris")
plt.show()
Vi kan finne gjennomsnittsprisen for disse årene ved å bruke pandas mean-metode på datarammen.
df["value"].mean()
120.7546762589928
Vi kunne også funnet gjennomsnittsprisen for årene 2000-2003:
# Vi lager en ny dataramme som kun har med de rader vi ønsker å behandle:
D = df[df["time"]>=2000]
D
| time | value | |
|---|---|---|
| 514 | 2000.000000 | 145.6 |
| 515 | 2000.019231 | 150.2 |
| 516 | 2000.038462 | 153.5 |
| 517 | 2000.057692 | 153.9 |
| 518 | 2000.076923 | 152.5 |
| ... | ... | ... |
| 691 | 2003.403846 | 157.9 |
| 692 | 2003.423077 | 160.4 |
| 693 | 2003.442308 | 159.1 |
| 694 | 2003.461538 | 160.9 |
| 695 | 2003.480769 | 161.7 |
182 rows × 2 columns
D["value"].mean()
141.87417582417586
Vi ser at gjennomsnittsprisen i perioden 2000-2003 er 141.87 dollar.
Eksempel 2¶
Filen https://vincentarelbundock.github.io/Rdatasets/csv/datasets/nottem.csv har data fra Nottingham slott. Den har to kolonner. Den første er tiden (i år) og den andre er temperaturen målt i Fahrenheit.
Vi ønsker å plotte temperaturen målt i grader Celsius som funksjon av tiden.
Vi bruker da følgende formel for å regne om fra Fahrenheit til Celsius:
import pandas as pd
import matplotlib.pyplot as plt
# Vi lager en dataramme med tallene fra filen:
url = "https://vincentarelbundock.github.io/Rdatasets/csv/datasets/nottem.csv"
df = pd.read_csv(url, index_col=0)
df
| time | value | |
|---|---|---|
| 1 | 1920.000000 | 40.6 |
| 2 | 1920.083333 | 40.8 |
| 3 | 1920.166667 | 44.4 |
| 4 | 1920.250000 | 46.7 |
| 5 | 1920.333333 | 54.1 |
| ... | ... | ... |
| 236 | 1939.583333 | 61.8 |
| 237 | 1939.666667 | 58.2 |
| 238 | 1939.750000 | 46.7 |
| 239 | 1939.833333 | 46.6 |
| 240 | 1939.916667 | 37.8 |
240 rows × 2 columns
# Vi legger til kolonnen med temperaturen i Celsius.
df["temperatur"] = 5*(df["value"]- 32)/9
df
| time | value | temperatur | |
|---|---|---|---|
| 1 | 1920.000000 | 40.6 | 4.777778 |
| 2 | 1920.083333 | 40.8 | 4.888889 |
| 3 | 1920.166667 | 44.4 | 6.888889 |
| 4 | 1920.250000 | 46.7 | 8.166667 |
| 5 | 1920.333333 | 54.1 | 12.277778 |
| ... | ... | ... | ... |
| 236 | 1939.583333 | 61.8 | 16.555556 |
| 237 | 1939.666667 | 58.2 | 14.555556 |
| 238 | 1939.750000 | 46.7 | 8.166667 |
| 239 | 1939.833333 | 46.6 | 8.111111 |
| 240 | 1939.916667 | 37.8 | 3.222222 |
240 rows × 3 columns
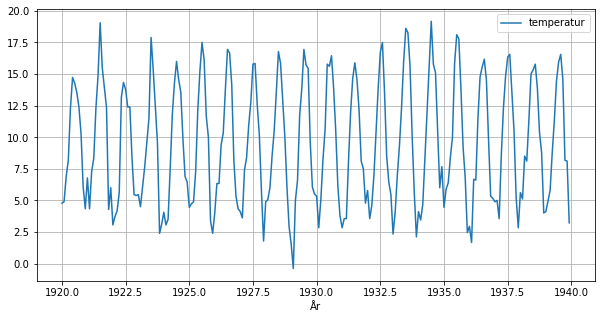
df.plot(x="time", y="temperatur", figsize=(10,5))
plt.xlabel("År")
plt.grid()
plt.show()
Oppgave 1¶
Hva var gjennomsnittstemperaturen i denne perioden?
Eksempel 3¶
På nettsiden seklima.met.no kan du laste ned klima-data for ulike målestasjoner. I dette eksempelet skal vi se på hvor kraftig det blåste i vindkastene i tidsrommet 26.-31. januar 2022.
Når vi har gjort de ulike valgene for hvilke data vi vil laste ned, så klikker vi på «Last ned» nederst til venstre på nettsiden. Velg csv-fil. Denne blir da lastet ned i din nedlastningsmappe (litt avhengig av nettleser og innstillinger). Pass på å ikke åpne denne filen med Excel. Dra så filen over i mappen som selve jupyter-filen din er lagret i.
Vi kan nå importere denne filen inn i Python, plotte og gjøre beregninger.
Når vi laster inn denne filen, får vi et par problemer. Vi må for det første spesifisere at verdiene skilles ved hjelp av semikolon. Dette gjør vi ved å skrive inn sep=”;”. Så får vi et lite problem ved at desimaltallene er gitt med komma, ikke punktum (som er standard i Python). Dette løser vi ved å skrive decimal=”,”.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("table.csv", sep=";", decimal=",")
df
| Navn | Stasjon | Tid(norsk normaltid) | Høyeste vindkast (10 min) | |
|---|---|---|---|---|
| 0 | E39 Stordabrua | SN48070 | 25.01.2022 19:30 | 5.9 |
| 1 | E39 Stordabrua | SN48070 | 25.01.2022 19:40 | 7.4 |
| 2 | E39 Stordabrua | SN48070 | 25.01.2022 19:50 | 8.2 |
| 3 | E39 Stordabrua | SN48070 | 25.01.2022 20:00 | 9.7 |
| 4 | E39 Stordabrua | SN48070 | 25.01.2022 20:10 | 11.2 |
| ... | ... | ... | ... | ... |
| 855 | E39 Stordabrua | SN48070 | 31.01.2022 18:30 | 10.1 |
| 856 | E39 Stordabrua | SN48070 | 31.01.2022 18:40 | 10.1 |
| 857 | E39 Stordabrua | SN48070 | 31.01.2022 18:50 | 12.3 |
| 858 | E39 Stordabrua | SN48070 | 31.01.2022 19:00 | 12.5 |
| 859 | Data er gyldig per 31.01.2022 (CC BY 4.0), Met... | NaN | NaN | NaN |
860 rows × 4 columns
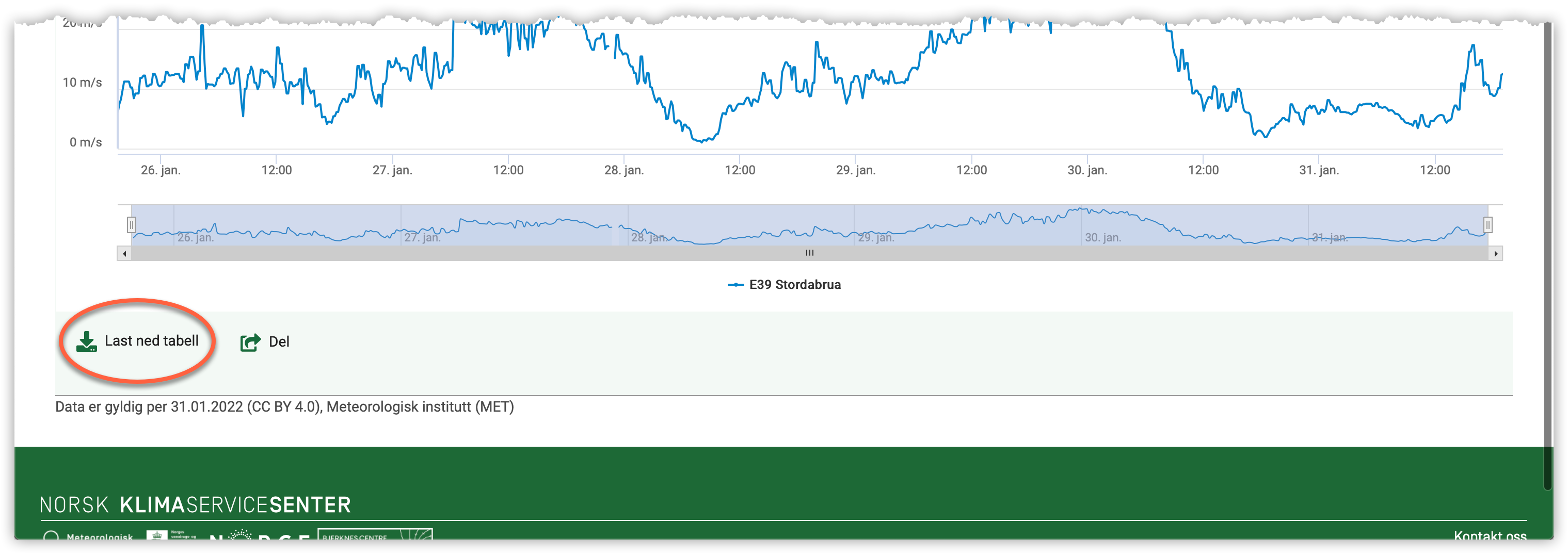
Vi ønsker nå å finne ut når vi hadde det høyeste vindkastet.
m = df["Høyeste vindkast (10 min)"].max()
m
35.0
for i in range(859):
if df["Høyeste vindkast (10 min)"][i] == m:
print(df["Tid(norsk normaltid)"][i])
29.01.2022 23:50
30.01.2022 00:00
Vi må selvsagt også plotte dataene våre:
df.plot(x="Tid(norsk normaltid)", y="Høyeste vindkast (10 min)", figsize=(13,5))
plt.grid()
plt.show()

Eksempel 4¶
Filen https://tork73.github.io/Data_behandling/vekt.txt inneholder vekten til 100 personer.
a) Bestem gjennomsnittsvekten til personene
b) Hva er den største vekten? Hva er den laveste?
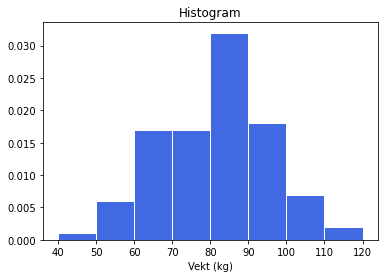
c) Illustrer tallene i et histogram.
import pandas as pd
import matplotlib.pyplot as plt
url = "https://tork73.github.io/Data_behandling/vekt.txt"
df = pd.read_csv(url, names=["Vekt"])
# a)
m = df["Vekt"].mean()
print(f"Gjennomsnittsvekten er {m:.1f} kg")
# b)
s = df["Vekt"].max()
print(f"Største vekt er {s:.1f} kg")
minste = df["Vekt"].min()
print(f"Laveste vekt er {minste:.1f} kg")
Gjennomsnittsvekten er 81.8 kg
Største vekt er 116.1 kg
Laveste vekt er 44.4 kg
plt.hist(df["Vekt"], bins=range(40, 130, 10), # bins er en liste med tall eller et helt tall
color="Royalblue", edgecolor="w", density=True)
# density=True gir en histogram med samlet areal lik 1
plt.xlabel("Vekt (kg)")
plt.title("Histogram")
plt.show()
Eksempel 5¶
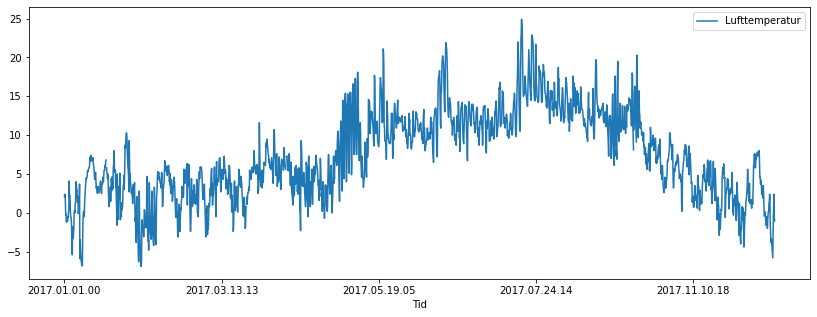
Filen https://tork73.github.io/Data_behandling/2017luft.txt inneholder målinter for temperaturen en plass gjennom et hele 2017. Den består av fem måliner for hver dag. Målingene er gjort klokken 00, 12, 15, 18 og 21.
Plott temperaturen gjennom hele året.
import pandas as pd
import matplotlib.pyplot as plt
url = "https://tork73.github.io/Data_behandling/2017luft.txt"
df = pd.read_csv(url, sep="\t", index_col=False)
df
| Tid | Nr | Lufttemperatur | |
|---|---|---|---|
| 0 | 2017.01.01.00 | 1 | 2.1 |
| 1 | 2017.01.01.12 | 2 | 2.4 |
| 2 | 2017.01.01.15 | 3 | 2.3 |
| 3 | 2017.01.01.18 | 4 | 1.3 |
| 4 | 2017.01.01.21 | 5 | -0.3 |
| ... | ... | ... | ... |
| 2255 | 2017.12.17.09 | 2256 | -0.2 |
| 2256 | 2017.12.17.12 | 2257 | 0.8 |
| 2257 | 2017.12.18.15 | 2258 | 2.4 |
| 2258 | 2017.12.28.18 | 2259 | -1.1 |
| 2259 | 2017.12.28.21 | 2260 | -0.9 |
2260 rows × 3 columns
df.plot(x="Tid", y="Lufttemperatur", figsize=(14, 5))
plt.show()
##$ Ekempel 6
Filen https://vincentarelbundock.github.io/Rdatasets/csv/quantreg/gasprice.csv innholder tidsserie for ukentlige bensinpriser i USA i perioden 1990:8-2003:26
a) Lag en grafisk framstilling av hele tidsserien.
b) Lag en grafiske gramstilling der du kun ser på årene 2000-2003.
import matplotlib.pyplot as plt
import pandas as pd
url = "https://vincentarelbundock.github.io/Rdatasets/csv/quantreg/gasprice.csv"
df = pd.read_csv(url, index_col=0)
df
| time | value | |
|---|---|---|
| 1 | 1990.134615 | 126.6 |
| 2 | 1990.153846 | 127.2 |
| 3 | 1990.173077 | 132.1 |
| 4 | 1990.192308 | 133.3 |
| 5 | 1990.211538 | 133.9 |
| ... | ... | ... |
| 691 | 2003.403846 | 157.9 |
| 692 | 2003.423077 | 160.4 |
| 693 | 2003.442308 | 159.1 |
| 694 | 2003.461538 | 160.9 |
| 695 | 2003.480769 | 161.7 |
695 rows × 2 columns
df.plot(x="time", y="value", figsize=(10, 5))
plt.xlim(2000)
plt.grid();
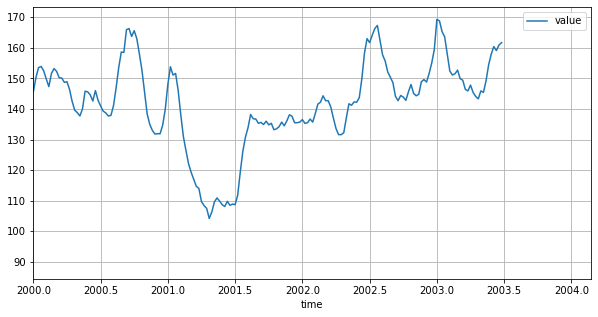
Vi kunne også ha laget en ny dataramme som inneholder kun data fra 2000-tallet:
df2 = df[df["time"] >= 2000]
df2.head()
| time | value | |
|---|---|---|
| 514 | 2000.000000 | 145.6 |
| 515 | 2000.019231 | 150.2 |
| 516 | 2000.038462 | 153.5 |
| 517 | 2000.057692 | 153.9 |
| 518 | 2000.076923 | 152.5 |
df2.plot(x="time", y="value", figsize=(10, 5));
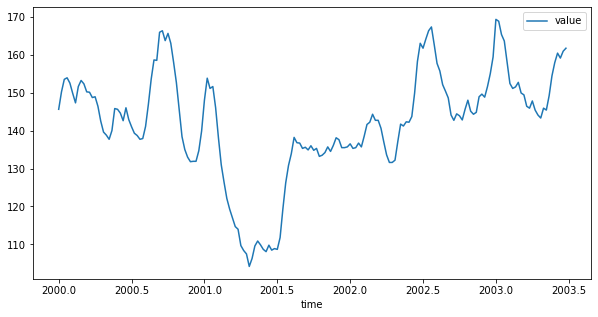
Oppgave 2¶
I denne oppgaven skal du jobbe med filen https: // tork73.github.io/Data_behandling/posisjon.txt.
a) Importer denne filen i et Pythonprogram.
b) Plott posisjonsgrafen som funksjon av tiden.
c) Plott fartsgrafen som funksjon av tiden.
import pandas as pd
import matplotlib.pyplot as plt
# a)
url = "https://tork73.github.io/Data_behandling/posisjon.txt"
df = pd.read_csv(url, sep="\t")
df.head()
| Tid(s) | Posisjon(m) | |
|---|---|---|
| 0 | 1.0052 | 0.727 |
| 1 | 1.1043 | 0.562 |
| 2 | 1.2037 | 0.434 |
| 3 | 1.3032 | 0.332 |
| 4 | 1.4029 | 0.261 |
# b)
df.plot("Tid(s)", "Posisjon(m)");
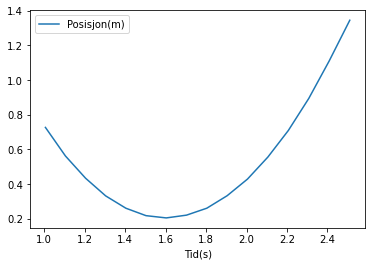
For å kunne tegne fartsgrafen må vi regne ut gjennomsnittsfarten i hvert delintervall fra df. Bruker da formelen
I vårt eksempel betyr dette at vi må regne ut endring i posisjon, delt på endring i tid. Vi lager derfor en ny liste som vi kaller Fart. I denne legger vi inn alle gjennomsnittsfartene. Vi lager også en liste som vi kaller Tid. I denne legger vi inn midtpunktet til tidspunktene.
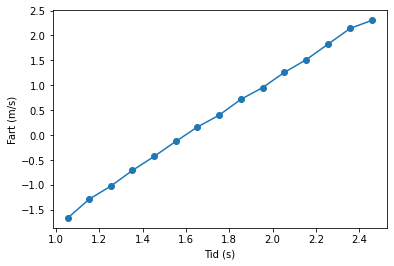
# c)
Fart = [] # Denne skal vi fylle med fartene.
for i in range(len(df)-1):
v = (df["Posisjon(m)"][i+1]-df["Posisjon(m)"][i])/(df["Tid(s)"][i+1]-df["Tid(s)"][i])
Fart.append(v)
Tid = [] # Denne skal vi fylle med midtpunktene til tiden.
for i in range(len(df)-1):
t = (df["Tid(s)"][i+1]+df["Tid(s)"][i])/2
Tid.append(t)
# Nå kan vi plotte data fra de to listene:
plt.plot(Tid, Fart, "-o")
plt.xlabel("Tid (s)")
plt.ylabel("Fart (m/s)")
plt.show()